結論:自律エージェントは「ループ」と「最小3要素」でできている
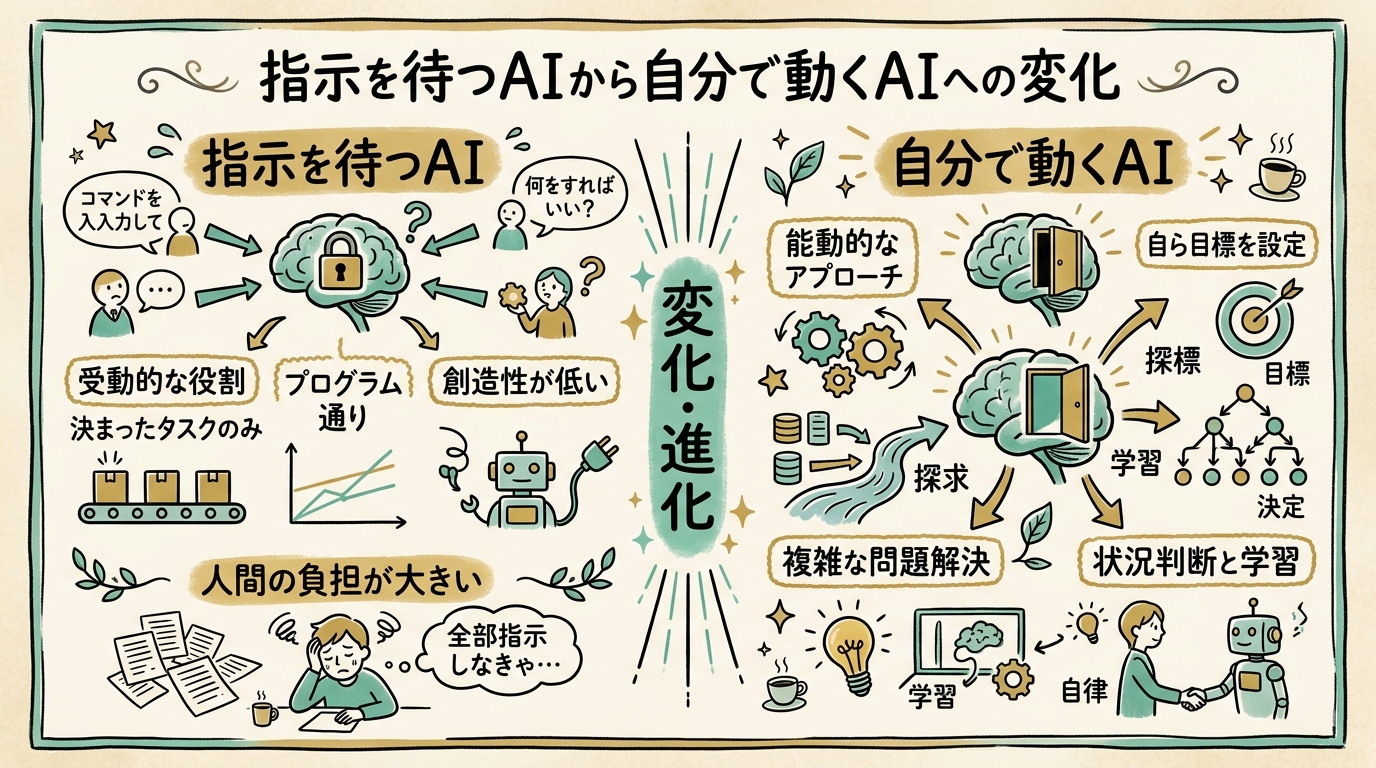
先に答えだけ書いてしまうと、自律エージェントは次のループの形をしています。
- プラン担当エージェント が、ゴールを見て計画を立てる
- 実装担当エージェント が、計画通りに手を動かす
- チェック担当エージェント が、出来上がりをゴール基準に照らして評価する
- ゴール未達なら、フィードバックを持って プラン担当に戻る
- ゴール達成、または回数制限に到達したら ループ終了
この骨組みを支える 最小3要素 が、本記事のいちばん持ち帰ってほしい部分です。
- チェック担当を別エージェントに分ける ― 同じLLMが書いて評価すると採点が甘くなる
- ゴール基準を明示する ― 曖昧だと永遠に止まらないか、早すぎて止まる
- 回数制限を入れる ― 無限ループとトークン爆発を構造的に防ぐ
これだけ押さえれば、特定のフレームワークやSDKに依存せずとも、自分の現場でループは組み立てられます。 この記事は 「読者が自分の業務に持ち帰って組める汎用パターン」 として書いています。コールテン社内事例は最後に1段落だけ。主役は読者の現場です。
対象読者は、技術寄りの経営者・AI担当として勉強し始めた方・エンジニアになりたての方。 コードは雰囲気を掴むための疑似コード中心です。動かさなくても大丈夫。
 Tiki
Tiki エージェントループの基本概念(Anthropic公式準拠)
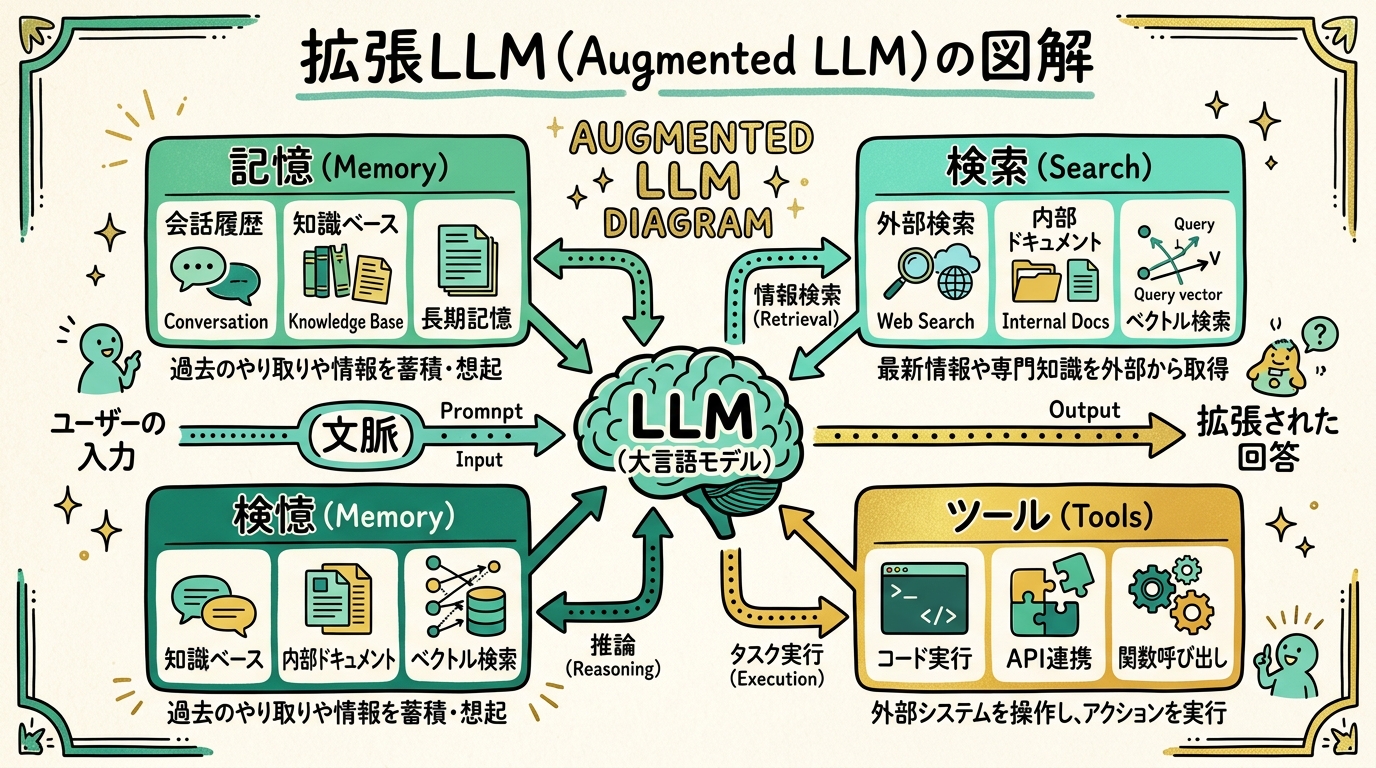
まず公式の整理から。Anthropicが2024年末に出した記事 「Building Effective Agents」 が、この分野の入門としてはもっとも参照されています。 ここでは 用語の定義をかなり丁寧に 書いてくれていて、ぼくも何度も読み返しています。
augmented LLM(拡張LLM)
一番ベースになる概念です。LLM単体ではなく、そこに 「記憶」「ツール」「検索」 といった要素を足したもの。 人間でいうと、頭の中だけで考えるのではなく、メモ帳・電卓・辞書・インターネットを使いながら考えている状態に近いです。
この augmented LLM が、エージェントの 最小単位 として位置付けられています。 派手な「自律」を考える前に、まずは「LLM + ツール」の組み合わせで何ができるかを把握するのが先、というのが公式の姿勢です。
workflows(ワークフロー)と agents(エージェント)の違い
次に、Anthropicは 「workflows」 と 「agents」 をはっきり区別しています。
- workflows:人間が事前に決めた手順に沿って、LLMとツールが流れ作業をする
- agents:LLM自身が「次に何をするか」を判断しながら進む
この違いはとても大事です。
workflowsは、決まった処理を確実にこなしたいときに向いています。流れが固定されているぶん、デバッグもしやすい。
agentsは、決まった手順では解けない・状況によって動きを変えたい問題に向いています。そのぶん予測しにくく、コストもかかります。
公式では 「まずワークフローで足りないかを検討してから、エージェントを使う」 ことが推奨されています。 派手な自律エージェントの記事が増える一方で、現場の8割は 「うまく組まれたワークフロー」 で十分、という感覚はぼくも持っています。
ループの中身:tool use → observation → reflection → action
エージェントが回しているループの中身は、ざっくり次の流れです。
- tool use(道具を使う):ファイルを読む、検索する、コードを動かす
- observation(観察する):道具を使った結果を見る
- reflection(ふりかえる):「いまどこまで進んだ?」「次は何をすべき?」を考える
- action(行動する):次の一手を決めて、また1に戻る
人間が仕事するときの動きとほとんど同じです。 この4ステップを、終了条件(目的を達成した/時間切れ/お手上げ)に当たるまで繰り返す。これがエージェントループの素朴なかたちです。
詳しい解説は、Anthropic公式ドキュメントの 「Sub-agents」 や、各種SDKドキュメントにあります。 この記事では概念を掴むのを優先して、実装の細部には踏み込みません。
事例:Webサイト修正ループ ― 3エージェントで「品質を保証する」
抽象的な話より、具体例のほうが頭に入ります。 ここからは、コールテンの現場でも実際に使っている 「Webサイト修正ループ」 を題材に、3エージェント構成を見ていきましょう。
シナリオ:クライアントサイトのデザイン崩れを直したい
想定はこんな状況です。
- クライアントから「トップページのレイアウトが崩れている」と連絡が入る
- 該当箇所はHero、ナビ、フッターあたり。スマホ表示で特に酷い
- 表示速度も遅くなっていて、ついでに直したい
- 明日までにステージング環境で確認できる状態にしたい
このタスクを、人間が手で全部やるのはしんどい。かといって、1つのAIに丸投げすると、たいてい 自分が書いたコードを自分でOKと採点して終了 してしまいます。 ここで効くのが、3つのエージェントによる役割分担です。
エージェント構成と各役割
ループに参加するのは、次の3エージェントです。
- プラン担当(プランナー) ― 現状のサイトと崩れの原因を調べ、修正の手順を計画する。何をどの順で直すか、影響範囲はどこか、を言語化する役割
- 実装担当(実装者) ― プランナーの計画を受けて、実際にコードを書き換える。CSSの調整、HTMLの構造修正、画像の最適化などを淡々とこなす役割
- チェック担当(チェッカー) ― 実装者の出力をゴール基準に照らして評価する。実装者と別エージェント で、独立した目線で点検する役割
ポイントは、チェック担当を完全に別エージェントとして立てる こと。 同じ会話セッション・同じLLMが書いて評価すると、自分の出力に対して甘くなります。これは人間が自分の文章を校正する時と同じで、構造的に避けがたい。だから別エージェントで切り出します。
ゴール基準を、複数の観点で書き出す
ループを回す前に、「何ができたら終わりか」 を必ず明文化します。今回のシナリオならこんな具合です。
- Lighthouse のパフォーマンススコアが 90以上
- デザイン仕様書とのdiffが 5箇所以内(許容範囲)
- 初期表示が 2秒以内(モバイル4G想定)
- 主要ブラウザ(Chrome / Safari / Firefox)でレイアウト崩れが視覚的に確認できない
- 既存のテストが全て通る
数値基準(Lighthouse・diff件数・表示速度)と、質的基準(視覚的に崩れていないか)の 両方 を書くのがコツ。 数値だけだと「スコアは出ているのに見た目がおかしい」を見逃すし、質的基準だけだと判定が甘くなります。
各ループでの動き
実際のループは、こんな流れで進みます。
- 1周目・プランナー:現状のCSSとHTMLを読み、崩れの原因を3つに分類。修正手順とリスクを列挙
- 1周目・実装者:プランの上から3項目を実装。コミット単位で出力
- 1周目・チェッカー:Lighthouse 86、diff 8箇所、表示速度2.4秒。視覚的な崩れも残る → NG。具体的に「フッターの余白」「画像のlazy load未適用」など指摘
- 2周目・プランナー:チェッカーの指摘を受けて、優先順位を組み直す。lazy load を最優先に
- 2周目・実装者:lazy load・余白調整・画像形式の見直しを実装
- 2周目・チェッカー:Lighthouse 92、diff 4箇所、表示速度1.8秒。視覚的な崩れも解消 → OK。ループ終了
この例では2周で収束しましたが、複雑なタスクだと3〜5周することもあります。 そこで効いてくるのが、最後の要素 ―― 回数制限です。これは後の章で詳しく見ます。
 テト
テト 最小3要素その1:チェック担当を別エージェントに分ける
ここから、最小3要素を順番に詳しく見ていきます。1つ目が チェック担当を別エージェントに分ける。 地味に見えて、ループ全体の品質を左右する一番大事なポイントです。
なぜ生成と評価を分けるのか
同じLLMが、自分の出した答えに対して採点する ―― この構造には根本的な弱さがあります。 人間でも、自分の書いた文章を自分で校正すると、誤字を見落としやすい。「自分で書いた文脈」 を頭が補完してしまうからです。LLMでも同じ現象が起きます。
だから、生成と評価は別人に任せる。これは伝統的なエンジニアリングでも、編集現場でも、ピアレビューという形で何十年もやってきたことです。AIエージェントでも、まずこの原則を踏襲するのが地に足ついた出発点になります。
チェック担当が見るべき観点
Webサイト修正ループの例で、チェック担当のプロンプトに入れる観点を並べてみます。
- 機能観点:要件通りに動くか、壊した既存機能はないか
- 性能観点:表示速度・スコア・メモリ消費が基準値以内か
- 視覚観点:レイアウト崩れ・はみ出し・色のずれがないか
- 整合観点:デザイン仕様書・ブランドガイドとの整合性
- 保守観点:コードが読めるか、命名は揃っているか、後から触れる構造か
観点を 言語化して渡す ことで、チェック担当の判断軸がぶれにくくなります。 逆に「いい感じか確認して」だけだと、評価の精度が一気に落ちる。これは人間にレビューを頼む時と同じ感覚です。
OK / NG / 部分OK の3値で返す
チェック担当の出力フォーマットも、最初に決めておくと運用が楽です。コールテンの社内では、こういう型を使っています。
- 判定:OK / NG / 部分OK のどれか
- 根拠:観点ごとの判定(数値があれば数値で)
- 次の指示:NGまたは部分OKなら、何を直してほしいかを具体に
特に 「次の指示」 がフィードバックとしてプラン担当に戻り、次のループの計画材料になります。 チェック担当が「NG」とだけ言って終わると、プラン担当は何を直していいか分からない。指示の解像度が、ループの収束速度に直結します。
同じモデルでもプロンプトで人格を変える
「別エージェント」と言っても、必ずしも違うLLMを使う必要はありません。 同じClaudeでも、システムプロンプトとロールを変えるだけで、別人格として機能します。実装の難度を上げる前に、同じモデル+別プロンプト でまず分離してみるのがおすすめです。
余裕が出てきたら、プラン担当には推論の強いモデル、実装担当にはコーディング特化モデル、チェック担当には別系統のモデル、というふうに使い分けると、評価の独立性がさらに上がります。コールテンでは、Claude / Codex / ローカルLLM(gemma系)をこの3役で混ぜることもあります。
最小3要素その2:ゴール基準を明示的に設定する
2つ目の要素が ゴール基準の明示。 これが甘いと、ループは2つの病気のどちらかにかかります。永遠に止まらない(チェック担当が常にNGと言い続ける)か、早すぎる終了(甘く採点してすぐOKを出す)か。
OK基準とNG基準の両方を書く
基準を書く時のコツは、OK条件だけでなくNG条件も書く こと。 「Lighthouse 90以上」がOK基準だとしたら、その裏で「警告が3件以上残っていたらNG」「主要ブラウザのいずれかでレイアウト崩れがあればNG」というNG基準も並べておきます。
片側だけだと、チェック担当はもう一方を 暗黙に解釈 しがちで、判断の解像度が落ちます。 例えば「読みやすい記事」というOK基準だけだと、「読みにくい」とは何かを毎回再定義することになる。「専門用語が3つ以上連続したらNG」「1段落が400字を超えたらNG」と書いておくと、判定がぶれません。
数値基準と質的基準を組み合わせる
基準は2種類に分けて考えます。
- 数値基準:テストの通過数、スコア閾値、diffの件数、表示速度のミリ秒、文字数
- 質的基準:文章の一貫性、デザインの統一感、ユーザー視点での読みやすさ
数値だけだと、機械的にはクリアしたのに人間の目で見ると違和感が残るパターンを見逃します。 質的だけだと、判定が主観的すぎてループが収束しません。両方並べて、どちらか一方でも未達ならNG にするのがバランスの取れた運用です。
「許容範囲」を組み込む
完璧主義の基準を書くと、ループはなかなか終わりません。 現実的には 「許容範囲」 を組み込むのが鍵です。「diffは5箇所以内ならOK」「Lighthouse 90以上で残りの警告は次回スプリントで対応」というように、どこまでなら妥協するか も基準として書く。
これは人間のチームでも同じで、「100点でないと出せない」と思っているプロジェクトが、結局リリースできずに終わるのと似ています。合格ラインを言語化する ことが、ループを安全に止める設計です。
基準は最初の1回で完璧でなくていい
ゴール基準は、最初から完璧を目指さなくて大丈夫です。1〜2周まわしてから、基準を更新する のが現実的。 「思ったより緩く採点された」「逆に厳しすぎて止まらない」と気付いたら、その都度基準を書き直します。チェック担当のプロンプトは、運用しながら磨いていくものとして扱うのが心地よいです。
Tiki 最小3要素その3:回数制限を入れる
3つ目が 回数制限。 「ゴール基準を書いたから止まるはず」と思っていても、実運用では 収束しない時 がどうしても出てきます。基準と実装力の噛み合わせが悪い、要件自体が矛盾している、外部環境が崩れている。理由は色々です。 そういう時の安全弁が、回数制限とトークン上限の組み合わせです。
max_iterations の妥当値
最大ループ数(max_iterations)の目安は、タスクの複雑さによって違います。 コールテンの社内運用での感覚値はこんな具合です。
- 単純な修正(誤字訂正・スタイル調整):3〜5周
- 中程度のタスク(Webサイト修正・記事リライト):5〜8周
- 複雑なタスク(新機能設計・調査レポート):8〜12周
これより多くまわす場合、たいてい 「そもそも要件が大きすぎる」 サインです。 タスクを分割して、それぞれを別ループで処理した方が結果が良くなります。
トークン上限と併用する
回数だけでは安全装置として弱い場面があります。1回のループで何千トークンも使うようなタスクだと、5周でもコストが膨らむ。 そこで 「最大ループ数」と「累計トークン上限」のAND条件 で止める設計にします。
例えば「最大5周、または累計1万トークン到達のどちらかで停止」という上限を仕込んでおく。Anthropic APIなら、レスポンスに含まれる usage から累積トークンを取り出せるので、ループの各ターンで合算して判定するだけです。
制限到達時のエスカレーション
上限に達した時の挙動も、最初に決めておきます。「黙って止まる」のは最悪の選択。 コールテンでは、次のような流れにしています。
- 上限到達を検知したら、これまでのプラン・実装・チェック結果を要約 する
- 残課題と推定原因を箇条書きで出す
- 人間にエスカレーション(Slack通知・メール下書き・ダッシュボード表示など)
- 人間が判断して、ループを再開するか・要件を見直すか・別アプローチに切り替えるかを決める
この「人間に渡す」設計が入っていると、暴走の心配なくループを回せます。 逆にここがないと、上限に当たった時に「何が起きていたのか」を後から追えなくなり、デバッグがとても辛くなります。
なぜ最小3要素なのか
ここまで見てきた3つ ―― チェックの分離・ゴール基準・回数制限 ―― は、互いに補い合う 関係にあります。
- チェックを分離するだけだと、基準が曖昧で永遠に止まらない
- 基準を書いただけだと、実装側がどれだけまわっても気付けない
- 回数制限だけだと、何が出来たのか・何が足りないのかが分からないまま終わる
3つが揃って、はじめて 「自律的に品質を保証するループ」 として機能します。 逆に言えば、この3つさえ押さえていれば、特定のフレームワークやSDKに縛られず、自分の現場の言語・ツールで組み立てられます。これが本記事のいちばん持ち帰ってほしい部分です。
30行で動くミニマム実装(3エージェント版)

ここまで読むと、「結局どんなコードになるの?」と気になってきたはず。 30行ほどで動く 3エージェント版のミニマム実装 を貼っておきます。雰囲気を掴むための疑似コード中心で、動かさなくても大丈夫です。
必要なもの
- Anthropic API Key(console.anthropic.com から取得)
- Pythonが動く環境(macOS / Windows / Linux どれでも可)
pip install anthropicで公式SDKを入れるだけ
フレームワーク不要。公式SDKだけで十分。最初はこっちのほうが、何が起きているか分かりやすいです。
30行ほどの最小コード(疑似コード寄り)
下記は、考え方を掴むための 雰囲気コード です。最新の公式SDKに合わせて細部は変わるので、動かすときは 公式ドキュメント を参照してください。
# minimal_loop.py(疑似コード・3エージェント版)
from anthropic import Anthropic
client = Anthropic()
goal = "トップページのレイアウト崩れを直す。Lighthouse 90以上、diff 5箇所以内"
def ask(role_prompt, user_msg):
res = client.messages.create(
model="claude-sonnet-4-7", max_tokens=1024,
system=role_prompt, messages=[{"role": "user", "content": user_msg}],
)
return res.content[0].text
plan, code, feedback = "", "", ""
for step in range(5): # 回数制限:最大5周
plan = ask("あなたはプラン担当。ゴールと前回フィードバックを踏まえ、修正手順を出す",
f"goal: {goal}\nfeedback: {feedback}")
code = ask("あなたは実装担当。プラン通りにコードを書く",
f"plan: {plan}")
judge = ask("あなたはチェック担当。ゴール基準で OK/NG を判定し、NGなら指示を出す",
f"goal: {goal}\ncode: {code}")
print(f"--- step {step} ---\n{judge}\n")
if "OK" in judge.split("\n")[0]:
break
feedback = judge # 次のループのプラン担当に渡す
else:
print("回数制限に到達。人間にエスカレーション。")やっていることは、こうです。
- ゴールを定義する(数値基準を含めて)
- プラン担当が、フィードバックを踏まえて計画を立てる
- 実装担当が、計画に沿ってコードを書く
- チェック担当が、ゴール基準でOK/NGを判定する
- OKなら終了、NGならフィードバックを次のループに渡す
- 5周まわしても収束しなければ、人間にエスカレーション
30行ほどでも、最小3要素(チェック分離・ゴール基準・回数制限)が全部入っている のが見えます。 これが分かると、後からどんなフレームワーク(LangChain / Claude Agent SDK / Mastra など)を見ても、中で何が起きているかの想像がつきやすくなります。
テト 次のステップ:ガードレール・観測ログ・人間レビュー
最小3要素でループは動きます。ただし、本番運用に近づけるには、もう一段の足し算が必要です。 優先順位の高い3つを並べておきます。
1. ガードレールを引く
エージェントが動ける範囲を、構造的に制限します。最低限の4つは次の通り。
- 書き込み先を限定する(特定のディレクトリ・ブランチだけ書ける)
- 実行コマンドを限定する(金融操作・本番デプロイ・大量削除は最初から外す)
- 外部送信は人間承認(SNS投稿・メール・チャット投稿は下書きまで)
- ログを必ず残す(後から追える状態を保つ)
この4つが揃っていない状態で「とりあえず自律で動かしてみよう」とやると、たいていどこかで小さな事故が起きます。 「まずガードレール、つぎにループ、最後に起動」 ―― この順番が、いまのところ一番しっくり来ています。
2. 観測ログを設計する
ループが回り始めると、「なぜこの判断になったのか」を後から追いたくなる場面が必ず出てきます。 観測ログとして残しておきたいのは次の項目。
- 各ループの 入力プロンプト(プラン・実装・チェックそれぞれ)
- 各エージェントの 出力 と判定結果
- 使用した トークン数とコスト
- ループの 所要時間(ボトルネックの特定に使う)
- 最終結果と、回数制限到達 / ゴール達成のどちらで止まったか
ログがあれば、「想定より高コストになっているループ」「いつもチェック担当が止めるパターン」など、運用改善の手がかりが見えてきます。これは人間のチームのふりかえりと同じ役割です。
3. 人間レビューの差し込みポイントを決める
すべてを自動化する必要はありません。人間が見るべきタイミングを最初に決めておく のが現実的です。
- 初回プランの確認:的外れな方向への暴走を初動で止める
- 回数制限到達時:自動エスカレーションで人間に渡す
- 外部送信の直前:SNS投稿・本番デプロイなど、外に出るアクションは必ず承認
逆に、内部のループ(プラン↔実装↔チェック)は人間が毎回見なくて大丈夫。 見守りが多すぎると、自律のメリットが消えてしまいます。「重要な分岐点だけ人間が立ち会う」 設計が、自律と安全のバランスを取るコツです。
余裕が出てきたら:メモリ設計
ループを何度も回していると、「過去にうまくいった判断・うまくいかなかった判断」を覚えておきたくなります。 短期メモリ(その日のループ内)、中期メモリ(プロジェクト単位)、長期メモリ(判断軸そのもの)の3層で考えると整理しやすいです。 ここは最小3要素が安定してから取り組む論点なので、最初は気にしなくて大丈夫。
始める前のチェックリスト

ここまでの内容を、明日から確認に使えるチェックリスト に落としておきます。 全部Yesでなくて大丈夫。最小3要素が揃っていれば、最初の1周はまわせます。
- チェック担当を、生成側とは別エージェントとして切り出したか
- ゴール基準を、数値と質の両方で書き出したか(OK基準・NG基準・許容範囲)
- 最大ループ数とトークン上限の両方を仕込んだか
- 制限到達時に、人間にエスカレーションする仕組みを入れたか
- 失敗していい場所(隔離されたフォルダ・ブランチ)を用意したか
- 書き込み先・実行コマンドを限定する設定を入れたか
- 外部送信は人間承認になっているか
- 各ループの入出力をログに残しているか
- 初回プランは人間が一瞥できる状態か
上から3つ(最小3要素)が揃ったら、まず1周まわしてみる。 そこから残りの項目を埋めていくのが、現実的な順番です。
次のステップ:もっと深く知りたい人へ

ここまでで「ループの感覚」が掴めたら、次に読むものは決まっています。 Anthropic公式 の3つです。最初に貼ったリンクをもう一度。
- Building Effective Agents(Anthropic Engineering) ― この分野の入門としてもっとも参照される記事
- Anthropic Docs ― API・SDK・エージェント機能の公式リファレンス
- Claude Code Sub-agents ― サブエージェント設計の公式ドキュメント
ループの感覚が手元にあると、これらのドキュメントが 「翻訳」 ではなく 「自分の経験の解説」 として読めるようになります。 逆に、感覚なしで読み始めると、用語の波で疲れます。30行の最小サンプルを 先に1回まわす のがおすすめです。
さらに踏み込みたい場合の方向は、ざっくり3つ。
- ツールを増やす:function calling / tool use を学ぶ
- サブエージェント化する:複数のエージェントが役割分担する設計に進む
- 常時稼働化する:cronやLaunchAgentで定期実行に乗せる(Lv4へ)
いずれも、「ループが回る感覚」 という土台があれば、自然と理解が追いつきます。 焦らず、一段ずつどうぞ。
テト あわせてこちらもどうぞ
自律エージェントや、AIをパートナーとして育てる関係づくりに関心のある方には、コールテンの伴走が役に立つかもしれません。 いきなり完全自律を目指す必要はなくて、「指示する関係」から「価値観を共有する関係」への一歩目を、無料の動画講座や3ヶ月プログラムで一緒に試していけます。
「自分の会社にも、こういう自律改善の仕組みって取り入れられそうですか?」という個別相談も歓迎です。 業種・規模・いまのAI活用度合いによって、ちょうど良い始め方は変わってきます。気になった方は、公式LINEから気軽に話しかけてみてください。
この記事は 2026-05-11 時点で、Anthropic公式ドキュメントの整理と、コールテンの社内運用(Webサイト修正ループ・Tiki Autonomous)をもとに書いています。SDK仕様や用語整理は今後も動く可能性があるので、運用の細部は適宜アップデートしていく予定です。
AI活用について公式LINEから無料相談OK
相談する関連記事
