1. はじめに ― 文字キャラに声をつける、という発想

コールテンには「AIの仮想チーム」がいます。30人くらい、各部門に担当者が散らばっていて、Slackや社内のドキュメントの中で日々喋っています。その中でも特に外向きに顔を出してきたのが、COSのTikiと、マーケ部長の盤上テト。SNSの吹き出しに登場し、ブログ記事の挿絵に出てきて、ロゴの横に並んでいる、あの2人です。
ふたりとも、しっかり「いる」感覚はあるのですが、ずっと声がありませんでした。テキストでは賑やかに喋っているのに、動画やショートを作ろうとすると、急に黙ってしまう。代わりに僕(Masaya)がナレーションを入れたり、既製の合成音声を借りてきたりしていました。
違和感が強くなったのは、ある日の夕方でした。動画の台本を眺めながら「この台詞、誰の声で読まれるんだろう」と止まったんです。テトのセリフもTikiのセリフも、全部Masayaの声で読み上げてしまうと、せっかくキャラを分けているのに音の中で混ざってしまう。それは、もったいない。
そこから「テトの声」「Tikiの声」を、ちゃんと作ろう、という方針が立ちました。プロの声優さんに依頼する選択肢もあったのですが、社内マスコットを長く育てていく前提だと、声色を後から細かく調整できる方が向いている気がしたんです。ブランドの一部として声を持つ。誰かのコピーではなく、テト/Tiki自身のものとしての声。それを、自前で作ってみたかった。
 盤上テト
盤上テト 2. なぜ既製の合成音声で済ませなかったのか
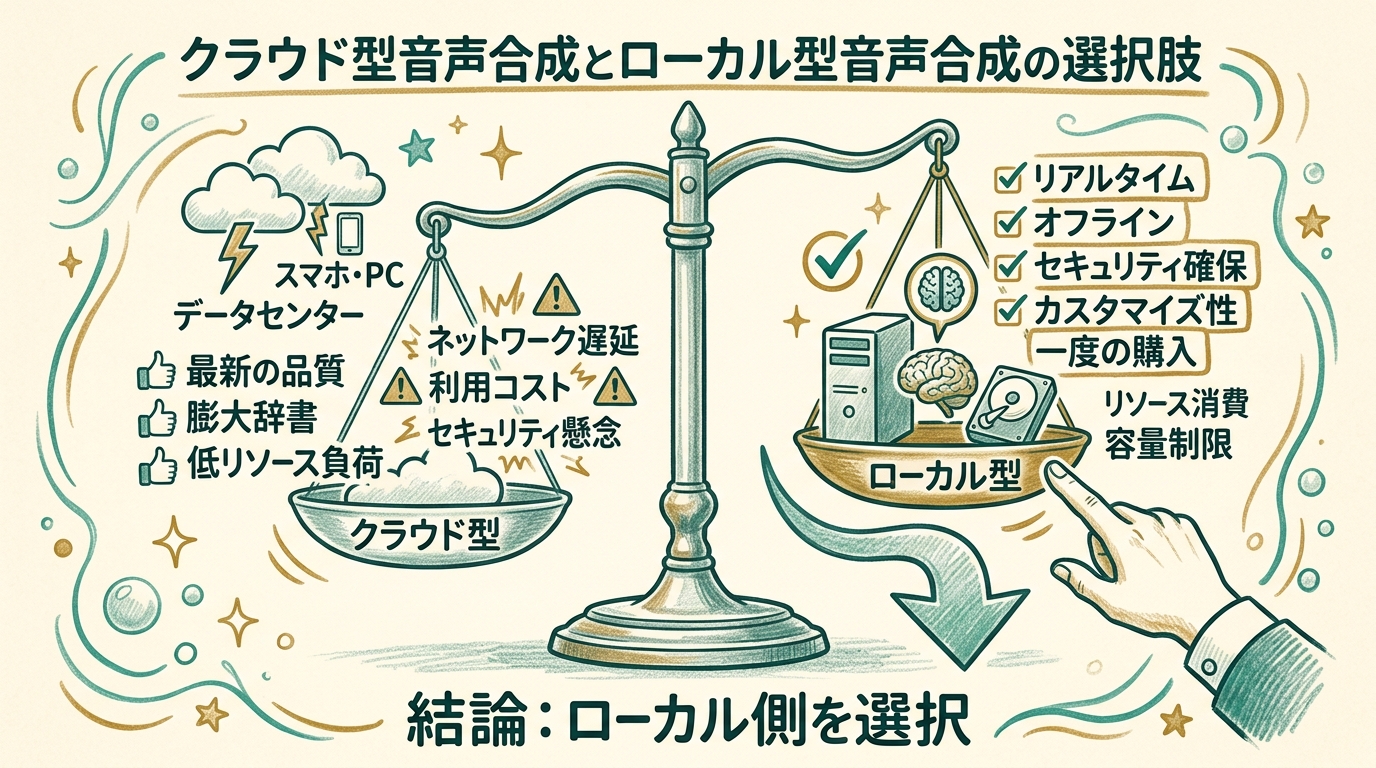
合成音声の選択肢は、いまわりとたくさんあります。クラウド型のサービスを使えば、文章を入れればきれいな声が返ってくるし、品質も日々上がっています。実際、しばらくはオープンソースのjvnvモデル(既製の声)を借りて凌いでいました。
ただ、しっくりこない。Tikiは「優しいけど芯のある中性的な感じ」が欲しい。テトには「マスコットらしい元気さ」が欲しい。既製品の声は、それぞれは魅力的なのですが、「うちのキャラの声」としては寄り切らないんです。ブランドの中で長く一緒にいるキャラは、声も一緒に育てたいと思いました。
すぐ使える。品質も悪くない。ただし「いいね、でもこれ、うちの子じゃないよね」という違和感が残る。声色を後から育てる余地はほぼない。
立ち上げに時間と手間がかかる。代わりに、声色を後から少しずつ調整できる。ベース素材を持っているので、テト・Tiki・将来のキャラへ派生もしやすい。
もうひとつの理由が、「キャラ拡張のしやすさ」でした。コールテンのAI仮想チームは、いま30名。そのうち外向きに名前が出るキャラはまだ少ないですが、これからエージェント増設・別キャラ立ち上げをするたびに「都度、別の声を借りてくる」のは継続性が弱い。同じ素材から派生させていけば、キャラの兄弟・姉妹のような声系統が組める。それが、自前を選ぶ決め手になりました。
ライセンス面でも、Style-Bert-VITS2はオープンソースで取り回しがしやすい立ち位置です。ただし他人の声を学習させるとか、商用に踏み込むときの線引きは別の話で、用途を広げるたびに公式ドキュメントを読み直すようにしています。便利だからこそ、入口の設計を雑にしないテーマだなと感じました。
2.5. 他サービスから声を借りる選択肢 ― メリット・デメリット

「キャラに声をつけたい」と決めたあと、最初に整理したのが「どこから声を借りる/作るか」の選択肢でした。自前学習に行く前に、ほかの道もちゃんと並べてみないと、本当に自前にすべきかが判断できなかったんです。
2026年5月時点でコールテンが検討した範囲を、横並びにしておきます。料金・ライセンス条件は時期によって変わるので、検討するときは各サービスの最新情報を必ず確認してください。
| 借り方 | 例 | 強み | 注意点 |
|---|---|---|---|
| 既製合成音声 OSS | jvnv-* / Voicevox公式キャラ | 無料・即使える | キャラ性が固定。ブランド差別化は弱い |
| 商用音声合成サービス | ElevenLabs / Resemble AI / Murf AI | 即運用、品質が安定 | 月額が継続的に発生。サービス依存 |
| 既存キャラ音声の借用 | VOICEROID系・キャラ商用ライセンス | キャラ性のあるカスタム化 | 権利元のライセンス条件遵守が必須 |
| プロ声優依頼 | スタジオ収録・ナレーション制作会社 | 最高品質・安定感 | 1キャラあたり数万〜数十万。修正の都度コスト |
| 自前ボイスクローン(本記事) | Style-Bert-VITS2 + Colab Pro | 資産化、低ランニング、モデル所有 | 学習コストが必要。品質は素材と時間次第 |
※ 各サービスの料金・商用条件は2026年5月時点の目安です。最新情報は公式サイトで確認してください。
並べてみると、それぞれに合う場面がはっきり分かれていきます。1本の動画のために、いますぐキャラの声がほしいなら、商用サービス(ElevenLabsなど)が圧倒的に速いです。キャラ性が固定でいい・無料で済ませたいなら、Voicevoxやjvnv系の既製OSSで十分なケースもあります。テレビCMや大型プロモーションの場面なら、プロ声優さんに依頼するのが一番安心です。
「他サービスから借りる」を検討するときに、僕がチェックリストにしていた項目を置いておきます。導入前にこのあたりを潰しておくと、後で困ることが減ります。
- 商用利用が許可されているか(個人利用のみのプランがあるサービスもあります)
- クライアントワークでの再販可否(自社利用OKでも、他社に成果物として渡せるかは別の話)
- 動画プラットフォームでの収益化可否(YouTube・TikTokでの運用に制限がないか)
- ブランドの「声」として独占的に使えるか(同じ声がライバル他社でも出てこないか)
- サービス停止時のフォールバック(提供元が止まったとき、これまで作った音声をどうするか)
コールテンの場合、最後の2つが特に大きかったです。テト・Tikiは長く一緒にいるブランドキャラなので、「同じ声が他社のキャラからも聞こえる」のは、できれば避けたい状態でした。それと、サービスが止まったとき、過去の動画やナレーションが資産として手元に残らないのは、長期運用のリスクとして無視できなかったんです。
逆に「短期のキャンペーン用」「使い捨ての試作動画」「社内通知ボット」のような用途なら、商用サービスやOSSの既製モデルで十分です。実際、コールテンでも「ブランド中核キャラだけ自前で持つ、用途特化のものは外注や既製モデル」という棲み分けに最終的に落ち着きました。
結論として、僕らはテト・Tikiという複数キャラのブランドアセットとして保有したかったので、初期コストを払って自前で作る選択肢を取りました。これは「自前が偉い」という話ではなくて、たまたま自分たちの優先順位が「資産として持つ」側にあった、というだけです。優先順位が「速度」や「安定品質」にある場合は、別の答えのほうが向いていると思います。
3. ツール選び ― なぜ Style-Bert-VITS2 だったか

音声合成のオープンソース実装はいくつもあります。VITS、VOICEVOX、Bert-VITS2、その派生……。最終的に落ち着いたのが Style-Bert-VITS2(以下SBV2)でした。理由はざっくり3つです。
- 日本語の表現力が高い: 抑揚や感情表現の出方が、日本語ネイティブのキャラ用途にちょうどよかった
- Colab で学習できる: 自前GPUを揃えなくても始められた。コストはColab Proの月10ドル定額のみ
- ローカルで推論できる: 学習済みモデルをMac miniに持ってくれば、API課金なしで何度でも喋らせられる
立ち上げの軽さでいえば、クラウド型サービスのほうがだいぶ楽です。SBV2は、Pythonの環境を組み、データを用意し、学習を回してから、ようやく音が出るという順番。慣れていないと、たどり着くまでに何度かつまずきます。実際、僕も最初の1週間は環境構築とエラー対応で15〜20時間くらい溶かしました。
それでもローカル型・自前学習にしたのは、声を「ブランドの一部」として持っていたかったから。立ち上げの早さで選ぶならクラウド型でしたが、テトもTikiも長く一緒にいるキャラなので、声も時間をかけて育つ前提で組みたかった。早く完成させるより、後から手を入れられる形で持っておきたい、という選び方になりました。
4. Tikiから始めた ― 「教訓を先に集めた」
最初に手をつけたのは、Tikiの声でした。理由は単純で、「最初にハマるなら、より重要なほうのキャラで、ハマりかたを全部経験しておきたかった」からです。テトを先にやって順調に終わってしまうと、Tikiで詰まったときに対処がわからない。順番をあえて逆にしました。
声の素材は、AIで生成した参考音声を使いました。「Tikiはこういう声であってほしい」というイメージを音声化して、それをSBV2に学習させる、という回りくどい手順です。30分ぶんくらい用意しました。
そしてここで、思っていたよりハマりました。Colabで作業していたのですが、エラーが連鎖するんです。具体的に詰まった場所を、思い出せる範囲で並べておきます。
pyopenjtalk_workerがランタイム上で立ち上がらないtorch.loadの仕様変更(weights_only周り)で、配布されている重みが読めないtorchaudio.AudioMetaDataがバージョンによって場所が違う- Colabセッションの揮発領域に学習結果を置いていて、セッション切れで消えた
- 依存ライブラリの相性で、片方を直すと別の場所が壊れる
エラーは出る。原因はずれて見える。修正したら別のところが壊れる。Colabの作業はこういうのが続きます。最初のうちは「うまくいったセル順を全部やり直す」しかなくて、毎回数時間が溶けていきました。
でも3週目あたりで、やり方を変えました。「失敗を覚える」のではなく、「失敗が起きにくい初期状態を毎回作る」。これが地味に効きました。
 Tiki
Tiki 5. 黄金パターンの確立 ― 失敗が起きにくい初期状態
「黄金パターン」と呼んでいるのは、要するに「学習を始める前に、毎回これを通せば、ほぼハマらない初期セット」のことです。具体的には、こんな項目を1つのColabノートブックに固定化しました。
- Pythonバージョンの固定(SBV2 が想定するバージョンを明示)
- 主要ライブラリのバージョンピン留め(torch / torchaudio / pyopenjtalk まわり)
- Google Driveをマウントし、学習結果は揮発しない場所に保存する設定
pyopenjtalk_workerの事前ウォームアップ- 音声データの前処理(書き起こしフォーマット・ファイル名規則)を決め打ち
- 学習途中で落ちた場合のレジューム手順を最初から組み込む
派手な工夫は何もありません。「過去の自分が踏んだ罠を、未来の自分が踏まないように、初期状態に対策を全部織り込んでおく」だけです。でも、これをやってからは、トラブル対応の時間が嘘みたいに減りました。
ポイントは、一発で成功させようとしないことだと思います。何度でも同じ条件で再開できる作業に分解しておくと、不確実性の高い作業(学習・推論調整)でも前に進めるようになります。学習は揺らぎがある以上、再現性を上げる側に時間を投資するのが結局一番速い、というのが学びでした。
6. テトも学習させる ― 二人目以降は3〜5時間で完走
Tikiで黄金パターンが固まったあと、テトの学習に入りました。同じノートブックを複製して、データだけ差し替えて、走らせる。Tikiのときは何日かかったか思い出せないくらいでしたが、テトは3〜5時間で完走しました。Colabで学習を回している間、僕は別の仕事をしていて、終わったらDriveにモデルファイルが保存されている、という状態です。
テトのキャラを声に落とすときに気をつけたのは、「Tikiから渡したい部分」と「テトに残したい部分」を切り分けることでした。具体的には、明るさ・軽さ・前のめりな抑揚みたいな成分はテトに、落ち着き・低めの安定感・間の取り方はTikiに、という形で系統を分けました。
学習データは1キャラあたり5〜10分の音声で十分でした。多ければ精度は上がりますが、品質と所要時間のバランスを考えると、最初は短めで試して、必要に応じて足すほうが現実的です。「いきなり完璧」より「試して足す」方が、結果として早く納得できる声に着地します。
制作にかかった時間とお金(だいたい)
| 項目 | 時間 | お金 |
|---|---|---|
| 環境構築・トラブル対応(最初の1週間) | 合計15〜20時間 | — |
| 黄金パターン確立後(残り3週間) | 1キャラあたり 実作業1〜2時間 + 学習待ち3〜5時間 | — |
| Colab Pro | — | 月10ドル |
| 合計(テト + Tiki 制作期間1ヶ月) | 正味30時間ほど | 10ドル |
声優さんに依頼することを考えると、コストの桁は2つくらい違います。もちろん、プロの仕上がりとは別物の話なので、単純比較はできません。ただ「社内のキャラを長期で育てる前提なら十分以上のコスト感」という手触りはあります。
7. キャラの「らしさ」を声に乗せる
学習が完了したあとは、キャラの「らしさ」を声に寄せていく調整作業です。SBV2はスタイル指定や話し方サンプルで、トーンや感情の出し方をある程度コントロールできます。「もう少し元気に」「もう少し軽く」「語尾の上がりを少しだけ強く」と、ダイヤルを回すような感覚で進めていきました。
テトとTikiでは、ダイヤルを回す方向が真逆でした。
- テト: マスコットらしい明るさ・軽さ・好奇心。語尾を少し上げて、テンポを早めに。子どもっぽさを残す
- Tiki: 優しく中性的な落ち着き。低すぎず高すぎず、間をきちんと取る。COSとして判断・対話の場に立つ温度感
面白かったのは、声が決まると、キャラの台詞そのものが変わってきたことです。文字で書いたときは違和感がなかったセリフが、声に乗せるとどこか硬く聞こえる。逆に、もっと砕けた言い回しのほうが声と馴染む。「テトはこういう喋り方をする子だ」というキャラ像が、声をきっかけにもう一段くっきりしました。
文字側が声側を作ったというより、声側が文字を作り直してくれた感覚です。これは、声を作る前は想定していなかった副産物でした。台本の書き方そのものが、ふたりに合わせて少しずつ更新されていきました。
Tiki 8. Before / After ― 既製モデル vs 自作の最新版

テトとTikiそれぞれ、同じ文言でBefore(既製モデル)とAfter(自作の最新版)を聞き比べられるようにしました。
| キャラ | Before(既製) | After(自作) |
|---|---|---|
| Tiki | jvnv-F1(オープンソース既製モデル) | tiki-v1(自作・100 epoch) |
| テト | jvnv-M1(オープンソース既製モデル) | teto-v1(自作・100 epoch) |
聴き比べると、キャラの「らしさ」が乗っているかどうかがわりとはっきり分かります。Beforeは「品質はいいが、誰の声でもない」感じ。Afterは「うちのキャラの声」になっていて、ちょっとアクセントが揺れたり抑揚が単調になったりしても、それが逆にキャラっぽさとして馴染んでいる。完璧さより、らしさのほうが効くんだな、という実感がありました。
9. 動画・SNS・社内利用 ― キャラ音声で何が変わったか
テトとTikiの声が立ち上がったあと、いきなり大きな場で使うより、社内のちょっとした場面でこっそり試して、馴染んだものから外向きに出していく順番にしました。声ができてから使い道がじわじわ広がっていった、という言い方が近いです。
| 場所 | 誰の声 | 使い方 |
|---|---|---|
| YouTubeショート・SNS動画 | テト中心、Tikiは合いの手 | 短いナレーション・キャラの掛け合い |
| ブログ記事の吹き出し | 両方 | 将来的に音声プレイヤー埋め込みを検討中 |
| 社内の議事録読み上げ | Tiki | 長文の振り返りを耳で聞き直す |
| 朝のブリーフ音声化 | Tiki | 移動中に予定と論点を聞きながら把握する |
| セミナー・教材の補助ナレーション | 用途で選ぶ | 自分が話すのが厳しい時間帯の代役 |
個人的に効いているのは、議事録の読み上げと、朝のブリーフ音声化です。文字で読むだけだと頭に入りきらない情報が、Tikiの声で耳から流れてくると、移動時間や家事の時間に少し進められる。これだけで「机に向かわないと進まない作業」のいくつかが、机の外でも進むようになりました。
ブランド面では、動画・SNS投稿のキャラ統一感が上がったのがいちばん大きいです。これまでは「画像はテト・Tiki、ナレーションはMasaya」という二層構造で、見ていてどこか分裂感があった。声がついてからは、画像・文字・音が同じキャラに紐づくので、視聴者の頭の中でもキャラが1人の存在として立ちやすくなった気がします。SNSのコメントでも「テトの声、想像と合ってた」と言ってもらえることが増えました。
10. やってみて気づいたこと ― 声には「キャラ性」が乗る

1ヶ月の作業を経て、いくつか気づいたことがあります。技術というより、キャラとの付き合い方の話です。
- 文字キャラと音声キャラは別物: 同じテトでも、文字で書かれたテトと声で喋るテトは、印象がけっこう違いました。どちらが本物かではなく、両方が組み合わさってキャラになっていく感覚です。
- 声が決まると、文体が引っ張られる: 喋ることを前提にすると、自然と短い文や砕けた言い回しが増えます。読むためだけに書いていた頃より、台詞が呼吸をしている感じになります。
- 不完全さが、かわいげに変わる瞬間がある: 抑揚が単調だったり、固有名詞でアクセントを外したりするのが、キャラの個性として馴染む場面が出てきました。完全に滑らかな声よりも、ほどよい揺らぎがあるほうがテトっぽい、という発見もあります。
- 失敗もちゃんとある: 学習データの偏りで、特定の語尾だけイントネーションがおかしくなったり、長文の途中で抑揚がリセットされたり。「録音時の癖が、そのままモデルに乗っている」と感じる瞬間が、地味に面白いです。
- 既製品で十分なケースもある: 社内の通知ボットや、使い捨ての試作動画くらいなら、jvnvなど既製品で十分でした。自前で作るのは、ブランドの一部として大事にしたいキャラだけでいい。これは、やってみて初めてわかったコスト感です。
もっと大きな気づきがひとつだけありました。声は、キャラの「もうひとつの輪郭」だったということです。始める前は、声は「文字キャラに後付けで足すアクセサリー」くらいに思っていました。実際にやってみると、声は文字とは独立したもうひとつの輪郭で、キャラを別の角度から立ち上げ直していました。文字側が声で書き直され、声側が文字で支えられる、相互作用みたいな関係です。
この感覚は、たぶんマスコットを持っているブランドや、AIキャラを運用している人全般に通じる話な気がします。「うちのキャラに声をつける」は、声優さんにナレーションを依頼する以上の意味を持つ。少なくともコールテンでは、テト・Tikiが声を持ってから、ブランド全体の手触りが一段変わりました。
盤上テト 関連する話・あわせて読みたい
この記事の周辺で、シリーズとして書いている話がいくつかあります。声づくりの話は、文字キャラの輪郭が育っていたこと、僕自身の声を別途クローンしていたこと、Mac mini中心の作業環境があったこと、それぞれの上に成り立っています。気になる入口から読んでもらえれば。
- 自分のボイスクローンを作った話 ― v1からv2へ、25分の録音で化けた瞬間(同時並行で執筆中の姉妹記事。代表ナレーション用に自分の声を学習させた記録)
- ティキちゃん、Tiki、盤上テト ― キャラ誕生秘話(テト・Tikiが文字キャラとしてどう立ち上がったかの背景)
- Mac mini 2台 + MacBook Air、3台で動く僕の作業環境(録音・学習を支えている裏側のセットアップ)
同じ景色を作りたい人へ
テトとTikiに声がついたことで、コールテンの中で「キャラを増やす」という遊びは、もう一段だけ先へ進んでしまった気がしています。文字だけで生きていた2人が、いまは耳の中にもいる。その変化は、想像していたよりずっと小さくて、けれど想像していたよりずっと大きい出来事でした。
もし「自分のマスコットにも声をつけてみたい」「事業のどこかに音声を組み込めないか考えたい」と感じた方がいれば、コールテンの公式LINEから気軽にご相談ください。AIをパートナーとして扱う前提で、どこから始めるのが現実的か、いまの体制でどこまで踏み出せそうか、一緒に整理していけます。
※本記事は2026-05-08時点の運用に基づいて整理しています。Style-Bert-VITS2のライセンスや音声合成サービスの仕様は時期により変わる可能性があるため、導入前は必ず最新の公式情報をご確認ください。
